mmap与read write对比
前几天在看malloc实现资料的时候,看到mmap,发现自己并不是非常理解mmap的作用,于是查了一些资料,顺便把以前的知识梳理一下,于是就有了这篇博文。
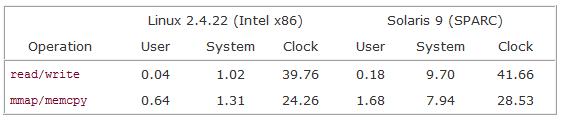
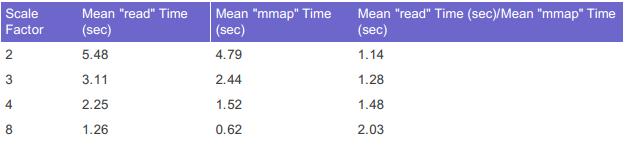
Linux下对文件的访问主要有两种方式。一种是read/write/seek,而另外一种是利用mmap系统调用将整个文件映射到内存中。[8][9]对比两种方式的性能,测试结果如图1、2所示。
mmap的优势
Stackoverflow上[2]有一个很好的讨论,对比read和mmap。总结一下 通常使用mmap()的三种情况(最终目的其实都一样:提高效率)。
提高I/O效率:传统的file I/O中read系统调用首先从磁盘拷贝数据到kernel,然后再把数据从kernel拷贝到用户定义的buffer中(可能是heap也有可能是stack或者是全局变量中[6])。而mmap直接由内核操刀,mmap返回的指针指向映射内存的起始位置,然后可以像操作内存一样操作文件,而且如果是用read/write将buffer写回page cache意味着整个文件都要与磁盘同步(即使这个文件只有个别page被修改了),而mmap的同步粒度是page,可以根据page数据结构的dirty位来决定是否需要与disk同步。这是mmap比read高效的主要原因。对于那种频繁读写同一个文件的程序更是如此。
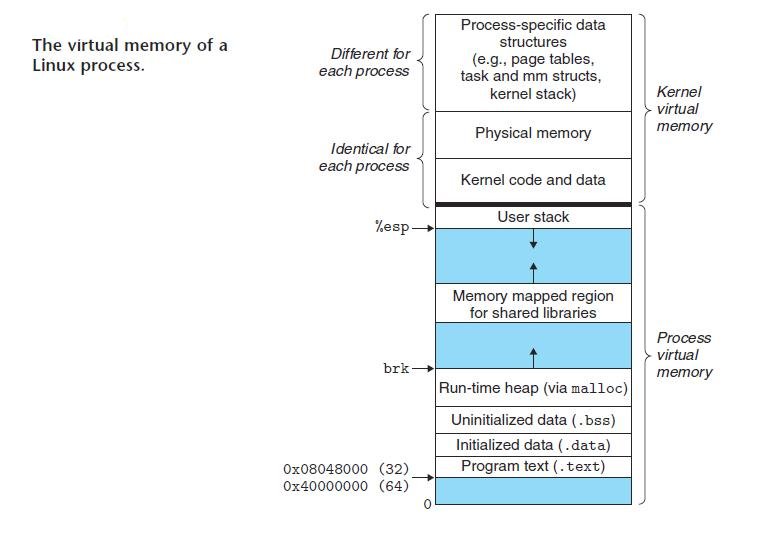
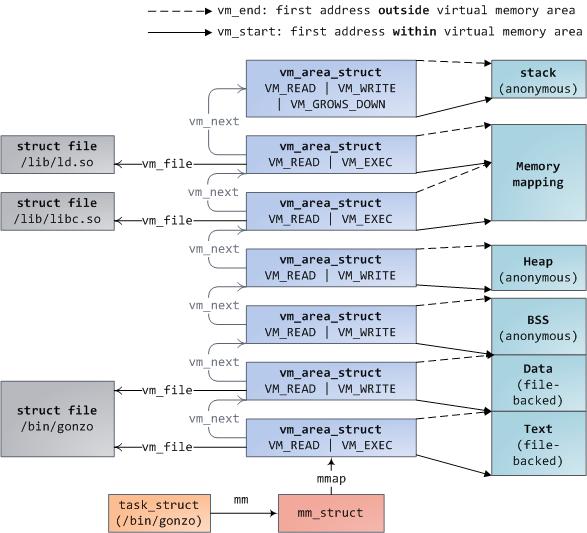
匿名内存映射:匿名内存映射有点像malloc(),其实Heap和BSS段就可以看成是一个anonymous mmap[图4]。有些malloc的实现中,当要分配较大的内存块时,malloc会调用mmap进行匿名内存映射,此时内存操作区域不是堆区,内存释放后也会直接归还给OS,不像heap中的内存可以再利用。匿名内存不是POXIS的标准,但是几乎所有的OS实现了这个功能。一个目前工人最好的malloc实现dlmalloc就是采用这种方式[4][5][6]。dlmalloc有三种分配方式:(1)小于64B的exact-size quicklist;(2)小于128KB的coalesce quicklist;(3)对于较大请求直接调用mmap。
共享内存进程通信:相对于管道、消息队列方式,通过内存映射的方式进程通信效率明显更高,它不需要任务数据拷贝。说到共享内存,还有一种System V保留下来的内存共享方法就是shmget相关系统调用。两者相比mmap更加简单易用一些,而shmget提供的功能更全面一些。
mmap的一些限制
当然mmap也有一定的限制。- mmap的对齐方式是page为大小的,有存在内存内部碎片的可能(调用的时候length没有对齐),所以mmap不适合小文件。
- mmap后的内存大小不能改变。当一个文件被mmap后,如果其他程序要改变文件的大小,要特别留意[8]。
- mmap不能处理所有类型的文件,例如pipes、tty、网络设备文件就不能处理。
- mmap要求进程提供一块连续的虚拟内存空间,对于大文件(1G)的内存映射。有时候会失败。尽管空闲内存大于1G,但是很有可能找不到连续的1G的内存空间。
- mmap对于那种批量写(write-only)的情景并没有优势。
[1]讨论了在传统的数据库中对数据库文件的相关操作“为什么不用mmap?”。传统数据库对datafile的读写大部分是通过open系统调用加O_DIRECT标志。使用O_DIRECT标志可以跳过kernel的page cache而直接与block device(如磁盘)打交道,与普通的read/write相比少了一层缓存(page cache),数据库开发者通过实现在用户层的高效缓存来达到提高效率目的。但是这带来很大的复杂性问题,首先使用O_DIRECT的话,就必须以页为单位进行I/O,而且既然放弃kernel的提供page cache以及相关的缓存策略,那么意味着是想通过O_DIRECT提供自己的更好的缓存策略,这个往往是很困难的。在Linus看来[12],“O_DIRECT是一个非常糟糕的接口,目前只为数据库开发者保留,其他人使用都属于脑残的行为”。数据库开发者想通过直接与device打交道(简单说,他们觉得能比OS干得更好),来提高IO性能,例如提供更适合数据库的缓存策略(如LIRS缓存算法[13])。例如Innodb中通过配置文件的形式提供了两种方式读写数据文件,一种是传统的read/write读写,一种是O_DIRECT访问。一般情况下O_DIRECT的性能要高[11]。
处理高并发的方案
在作者看来,用mmap管理是一个可行的方案:使用mmap可以减少kernel 与user space 之间的context switch;kernel提供了page cache高效的缓存管理;内存被共享时kernel提供了同步功能。除了mmap,配合mlock()、madvise()、msync(),开发者能够更自由的控制缓存策略。像MongoDB就是使用mmap来读写数据文件的。但是由于使用madvise的人不多,kernel好像并没有利用madvise信息,或者效果不是很好[12]。 文中最后提了这种方式如何应对高并发的请求,并提了一些解决方案。
Coroutine,用户级的协程的好处就是比thread的开销更小,但是有一个很大的问题,一旦一个协程调用系统调用阻塞时(如等待IO),协程所属的线程就会阻塞,也就意味着其他协程也要跟着阻塞。这里有几种解决方案:
- 如果能够容忍阻塞对性能的影响,就不做处理:)。
- 为阻塞的协程新建一个内核线程专门等待系统调用完成,这样其他协程就可以继续, Goroutine采用的就是这种机制[?]。
- 使用NonblockingIO,文中提到了epoll+eventfd[14]。Epoll是linux下的一种多路复用技术,功能与select,poll一样,eventfd则与pipe有点像,它通过创建的事件对象来读写一个64位的整数计数器,线程之间通过协商好事件对应的数值来协调通信。
- 对于O_DIRECT访问Disk,使用异步IO,当然也可一配合epoll使用。
[1]文中的评论给出了一些不同看法: 1. 频繁的使用mmap会很容易耗尽内存的资源,特别对于32位的机器。作者提出可以使用cgroups[15]来控制资源的使用。 2. Mmap并不适合那种write-only的场景,或者说这个时候没什么性能优势,而database的commit log就属于这一类型。 3. Mmap不能提供一些灵活的控制缓存的需求,例如控制不同缓存块的写入顺序等等。
Page Cache
上文的讨论中,涉及到一个很重要的概念——Page Cache,简单概括,就是磁盘的数据以页式缓存的形式保存在内存中。可以从两个方面去理解Page和Cache。
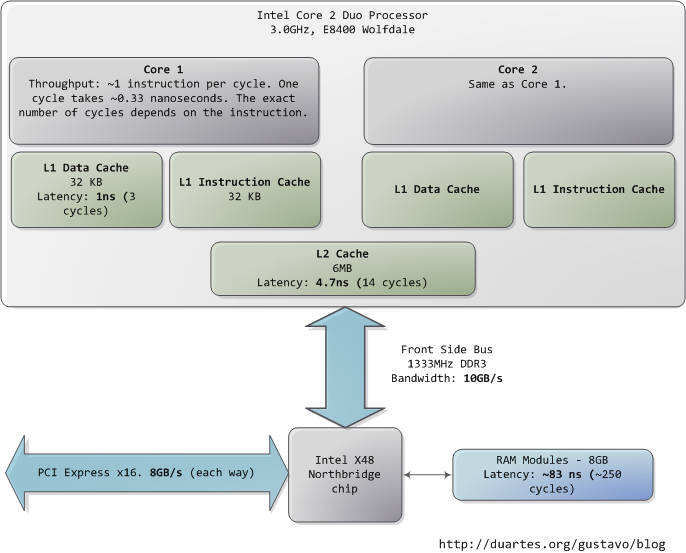
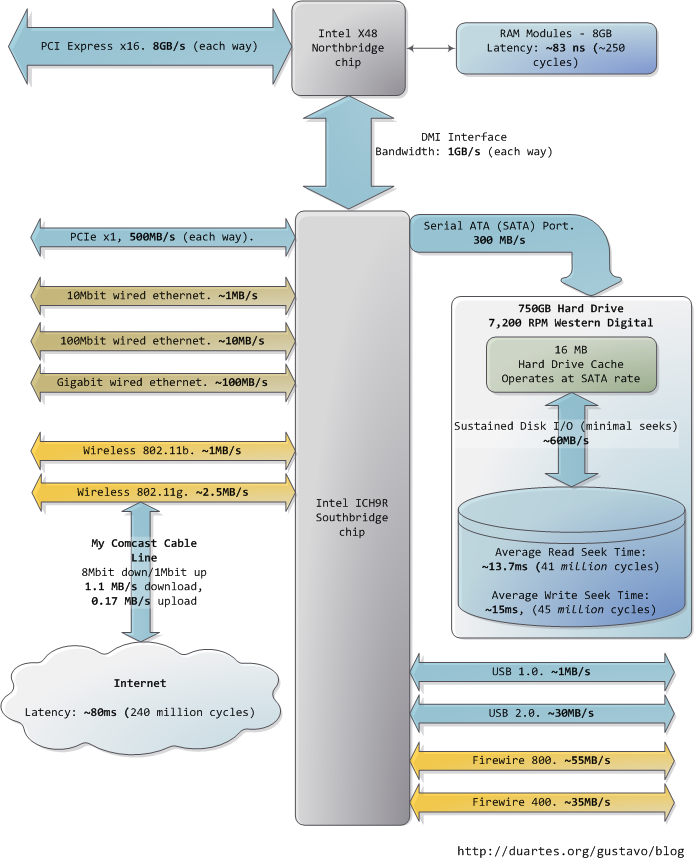
Cache:缓存存在的最主要目的为了解决设备读写速度不均横的问题。例如内存可以理解为Disk等设备的缓存,CPU Cache可以理解为内存的缓存。图5给出了传统计算机各个部件的速度,非常的直观。简单说一个好的缓存设计可以大大提高系统IO的性能。
Page:Page是Disk block在内存中的缓存结构,类似的Cache Line是内存数据在CPU Cache中的缓存单元。一般Page大小是可配置的,一般是Disk block的倍数,但是一个Page对应的多个block在Disk中不一定是连续的。
一个高效的缓存,必然会涉及到几个问题。
缓存替换算法:最有名莫过于LRU(Least Recently Used)算法,但是LRU在批量读写大文件的时候,会清空当前缓存,而如果读取的打文件只是读取一次,那么意味着之前缓存的数据又要从磁盘重新读取,为了避免这种情况Kernel使用两条链表,一条Hot链表,存的是被访问一次的以上的数据,而另一个链表存放第一次读取的Page,两个链表都使用LRU算法。
数据写回侧策略:主要两种:write through和write back。Kernel为了效率使用write back。后台使用flush线程将page cache与磁盘等设备同步。有三种情况会触发这个同步线程:1,内存空闲(未与磁盘同步)页表数低于系统设定阈值;2,dirty 的页在内存中存在超过系统设置的时间;3,用户调用sync(),fsync()系统调用。Linux Kernel中flush的线程数目等于系统磁盘(持久化设备)的个数,其实同步线程有一个演化的过程,从bdflush和kupdated配合使用到动态个数的pdflush线程再到现在的与外部设备等个数的flush线程。具体可参考[17]。
如何高效判断数据已在缓存中:Kernel中使用Radix Tree进行索引,在2.6版本以前使用全局的Hash Table效率较低。现在是每个文件都会有一个radix tree。提供一个文件的偏移值(偏移值对应radix tree的key),可以在常数(与偏移值的位数有关)时间内找到对应的page项,如果没有,则先分配一个,再返回,并且每个page项表明了是否dirty等信息。Radix Tree是Trie的压缩版本,Trie是一个节点一个字符,Radix Tree允许多个字符。
有关Page Cache的更细节的东西,可以参考《Linux kernel development》[17]13章。
Reference
[1]: Why not mmap[2]: When should I use mmap for file access
[3]: Wikipedia of mmap
[4]: quora: what is a good implementation of malloc
[5]: dlmalloc-A Memory Allocator by Doug Lea
[6]: A handout of memory allocation
[7]: 我的笔记:OS Thread
[8]: Advanced Programming-Unix Environment 2ed
[9]: read VS mmap
[10]: 《大规模分布式存储系统——原理解析与构架实践》 杨传辉
[11]: Direct I/O in InnoDB (O_DIRECT)
[12]: Linux Kernel Maillist 上Linus关于O_DIRECT的讨论
[13]: LIRS caching algorithm
[14]: A example usage of epoll with eventfd
[15]: Wikipedia of cgroups
[16]: How the kernel manages your memory
[17]: Robert Love《Linux Kernel Development》第三版 comments powered by Disqus